
Welcome to Alex Romriell's Website
I am a data scientist with a background in chemical engineering. I have five years of experience as a data analyst/production engineer for a chemical manufacturing facility. I am about to complete a Master’s degree in Data Analytics at USF.
A little about me technically, I am confident in pulling data from disparate sources into one convenient, easy-to-access location. My skills include: cleaning, analyzing, and visualizing large datasets in Python (numpy, pandas, scikit-learn), R, SQL, D3, Spark, SAS, Tableau, Microsoft Office products, and distributed systems on AWS. I have a strong understanding of many machine learning models and statistical analysis. I am a quick learner and willing to adapt to various technology and programming changes.
Personally, I am easy-going, work well in teams, and am motivated to continue working until I have a fantastic end product. I enjoy teaching others who are not technically trained about how data can help them make decisions. I am fluent in English and Korean. My favorite projects to work on so far have been data visualizations, maps, and recommendation systems. Please enjoy browsing through some of the projects I have completed thus far and feel free to contact me with any questions.
Emotion Recognition

My team and I wrote our own convolutional neural network to detect emotion in still images. We achieved 96% classification accuracy for binary emotion detection (i.e. happy vs. not happy) and 67% classification accuracy when seven emotions were present. View the report and presentation on Github.
Maximize Auction Payout
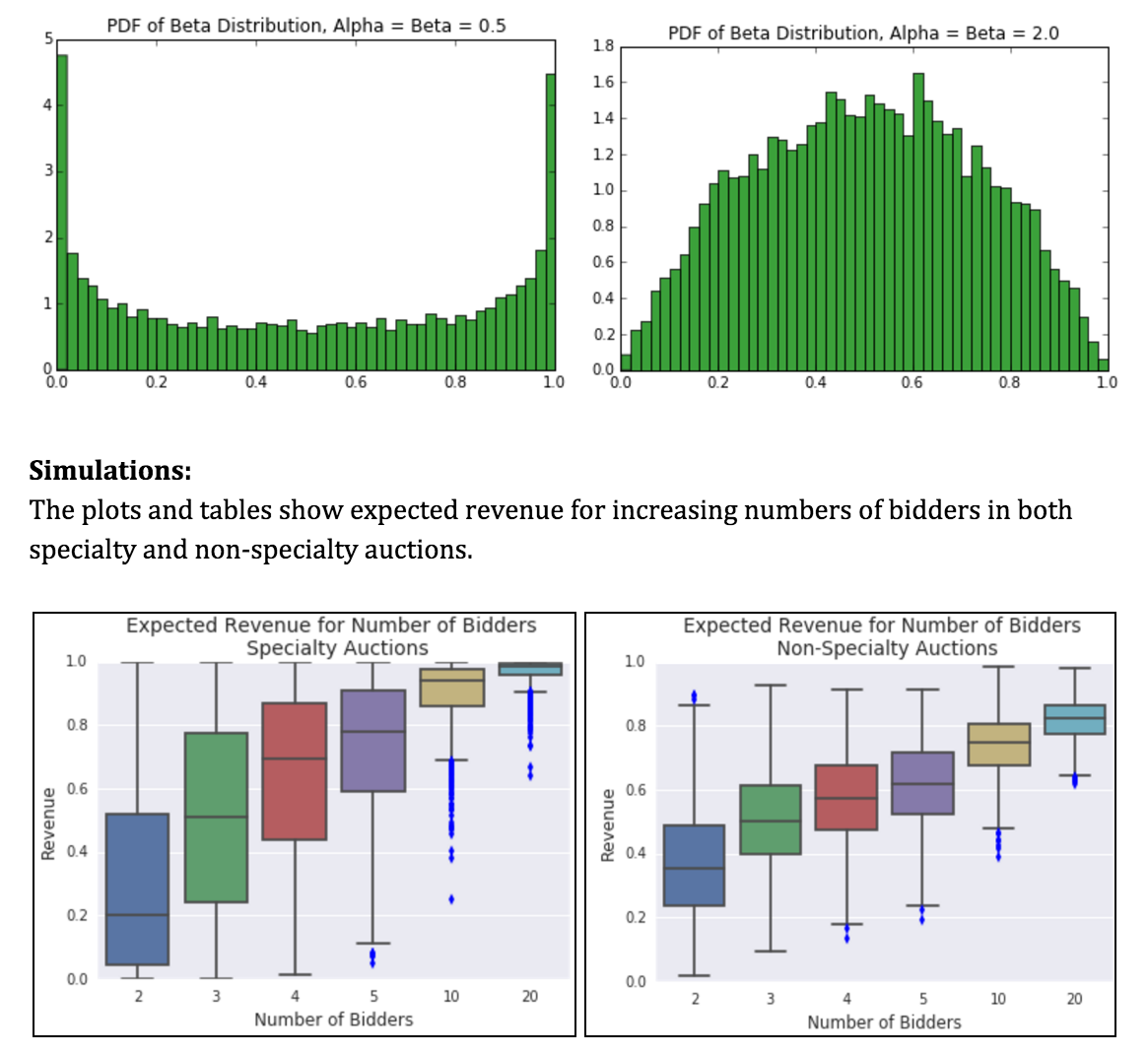
The beta distribution closely models the distribution of values expected in a specialty items auction. Ad agencies and other bidding platforms can use this distribution to estimate and maximize expected payout.
Best Subset Regression
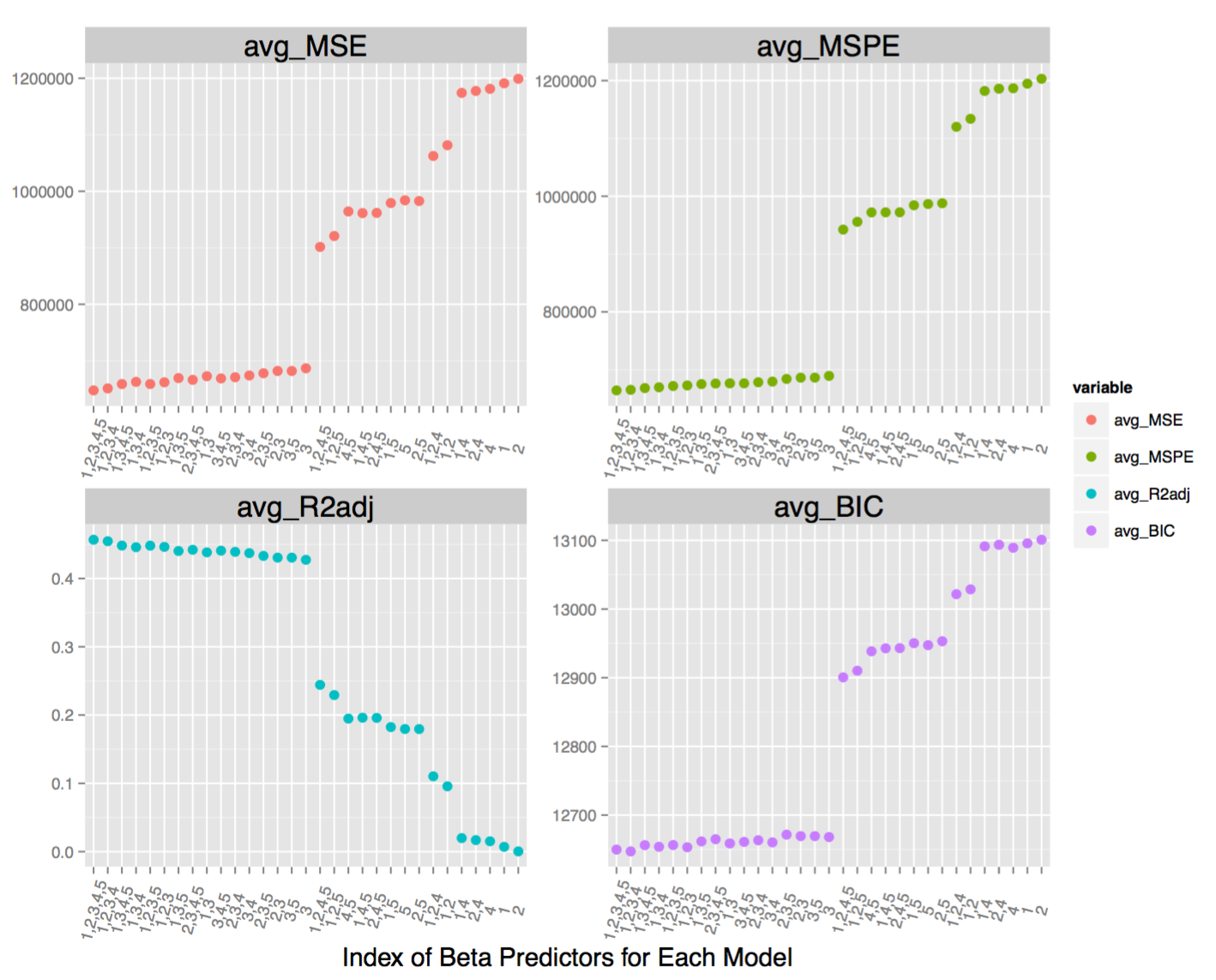
Here I wrote my own cross-validation function, best subset, ridge, and lasso regression methods in R. Each method was used in order to find leading indicators to predict room and board costs for over 700 Colleges and Universities across America.
Bankruptcy Rates Time Series Analysis
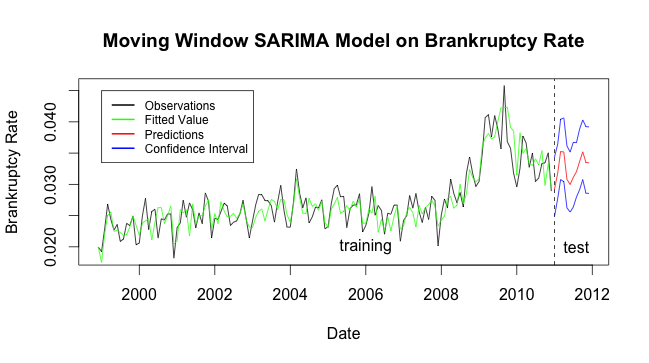
In this project my team and I predicted 2011 Canadian bankrupty rates using historical data from 1987-2010. The SARIMA model gave us our best fit (Seasonal Autoregressive Moving Average model)
Linear Regression Case Study
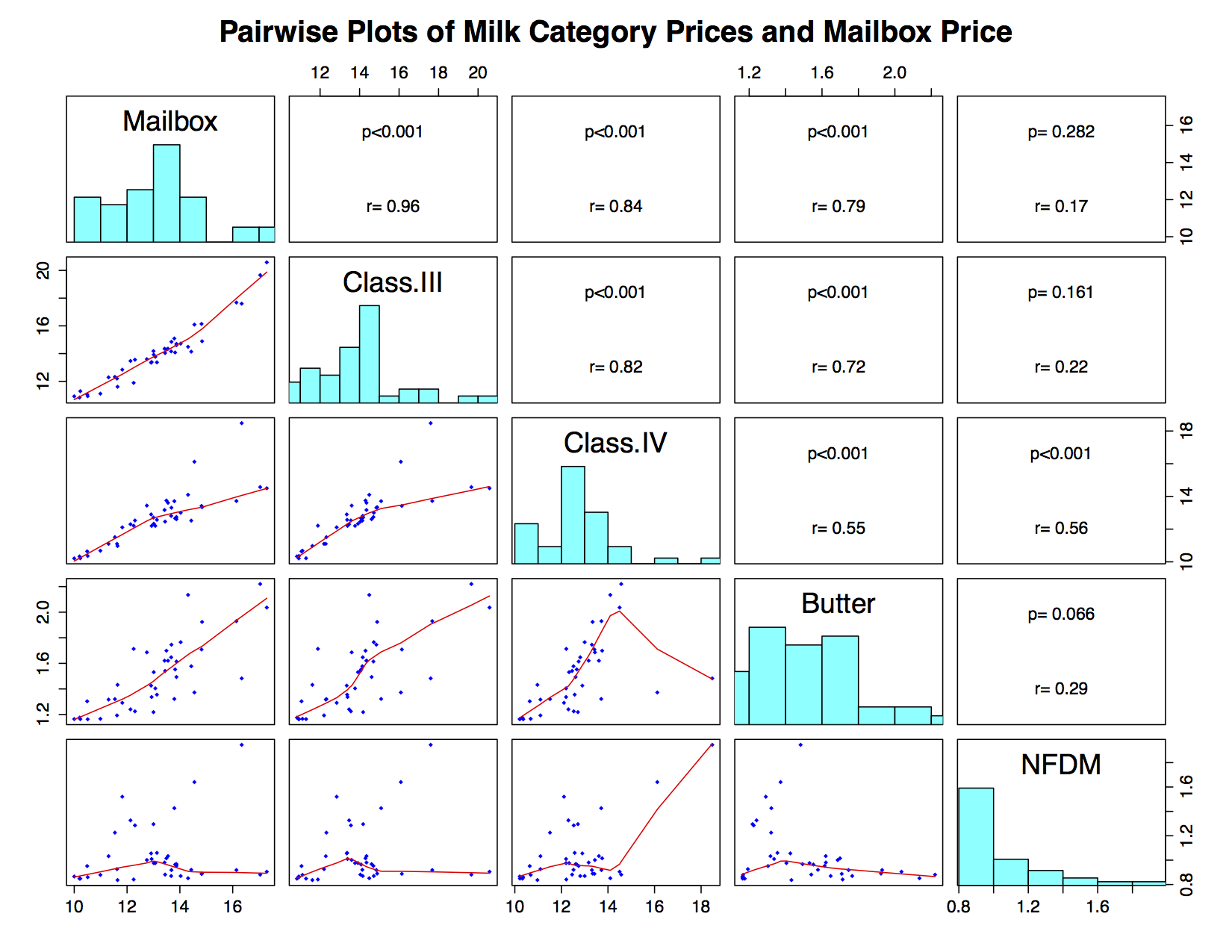
This is a case study determining the optimum strike price for dairy products. There are several mercantile exchanges with different measurement units, as well as varying state regulations. This model uses this information to forecast strike prices which effects monthly production rates.
Gradient Descent
Simulation

Gradient descent is commonly used for maximizing/minimizing models. Here is a simulation showing one pitfall of gradient descent: local minima. To avoid this, I used cross- validation with random starting points.
World's Data Breaches
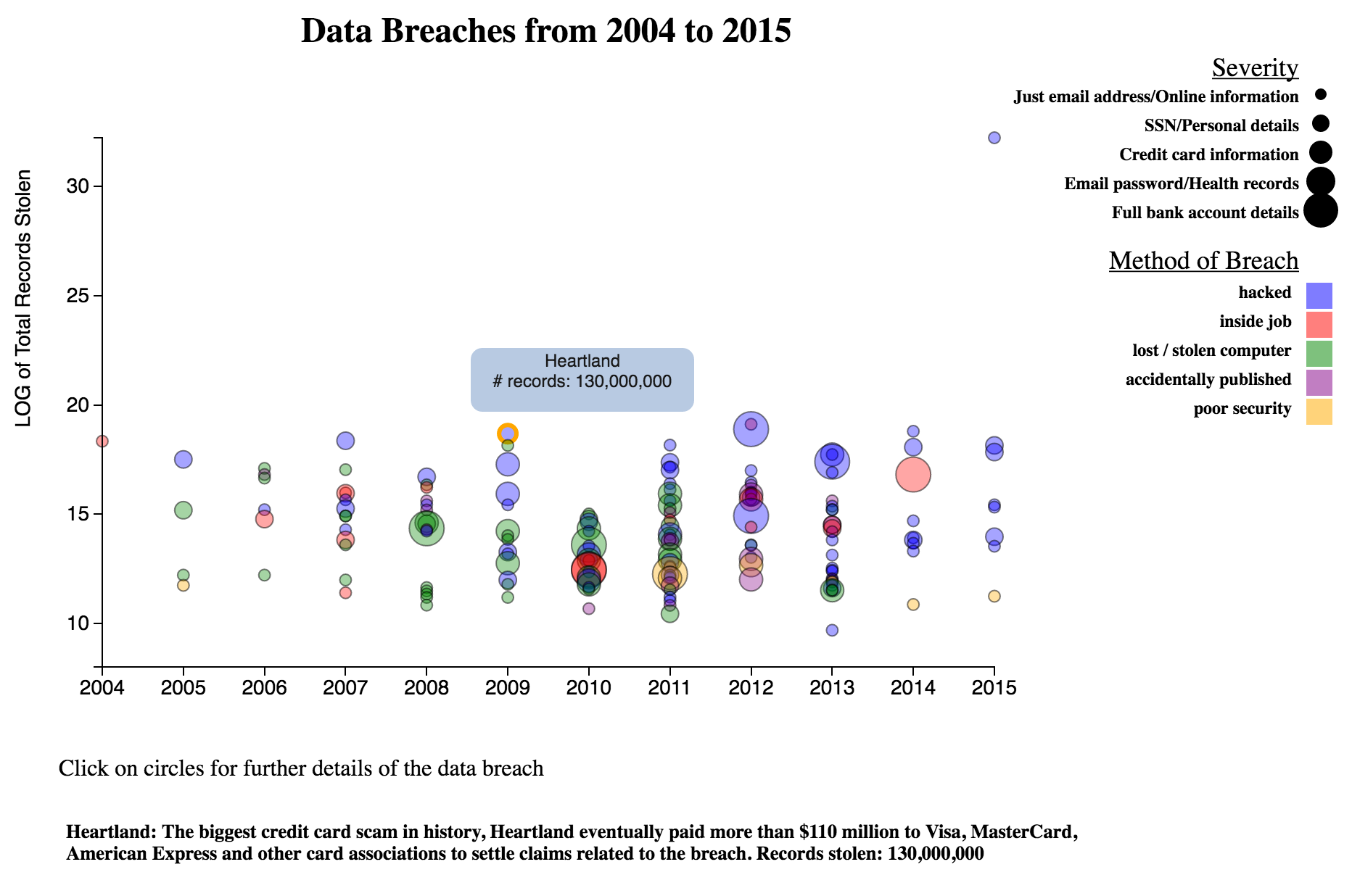
This is a visualization of some of the world's largest data breaches from 2004 - 2015, broken down by method of breach and severity of breach.
The data-set comes from the Information is Beautiful website.
Bike Parking in SF
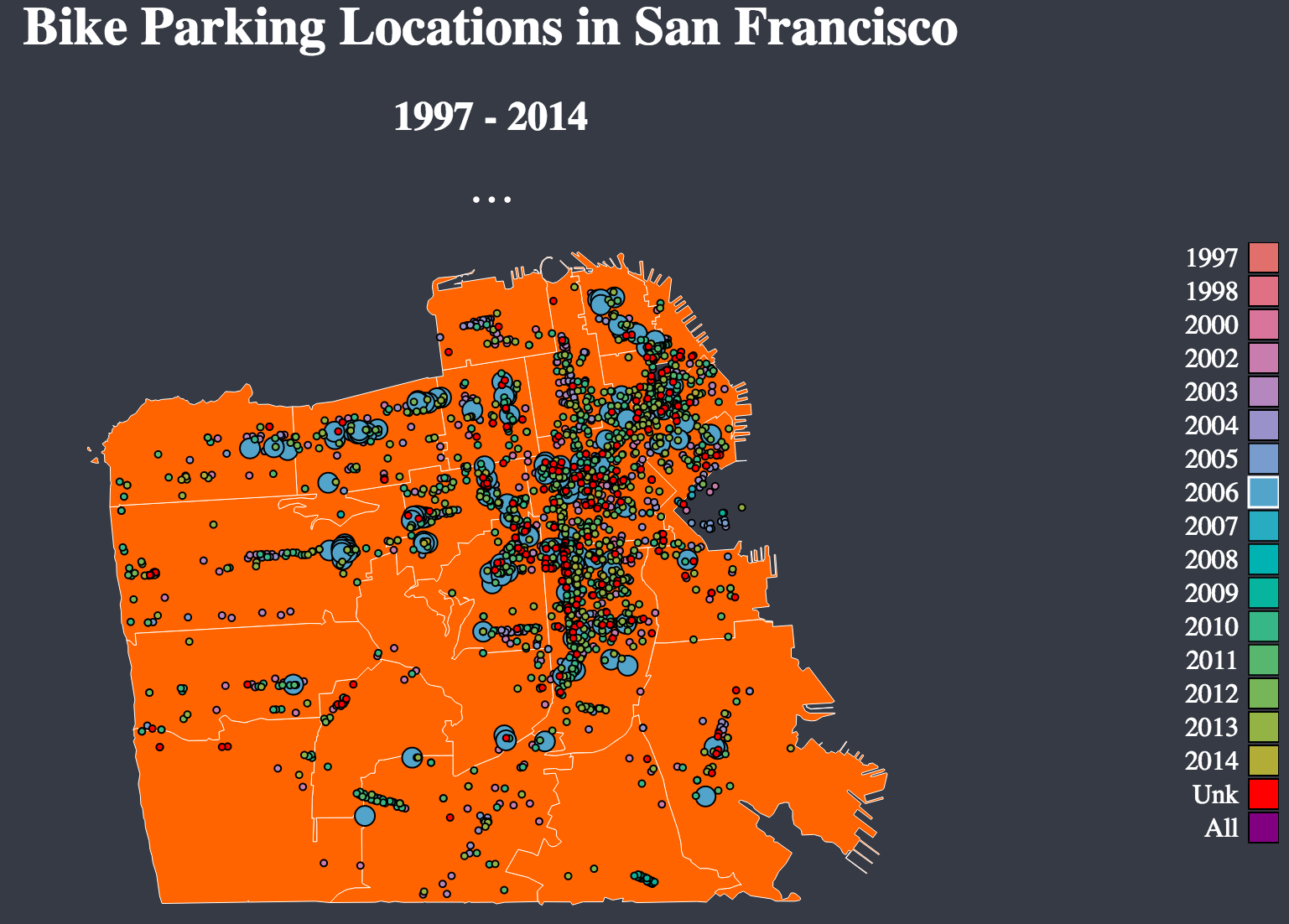
Here is an interactive map showing the growth of bike parking locations over the past 15 years.
The data-set comes from the SF Data Portal: data.sfgov.org
D3 Data Dashboard
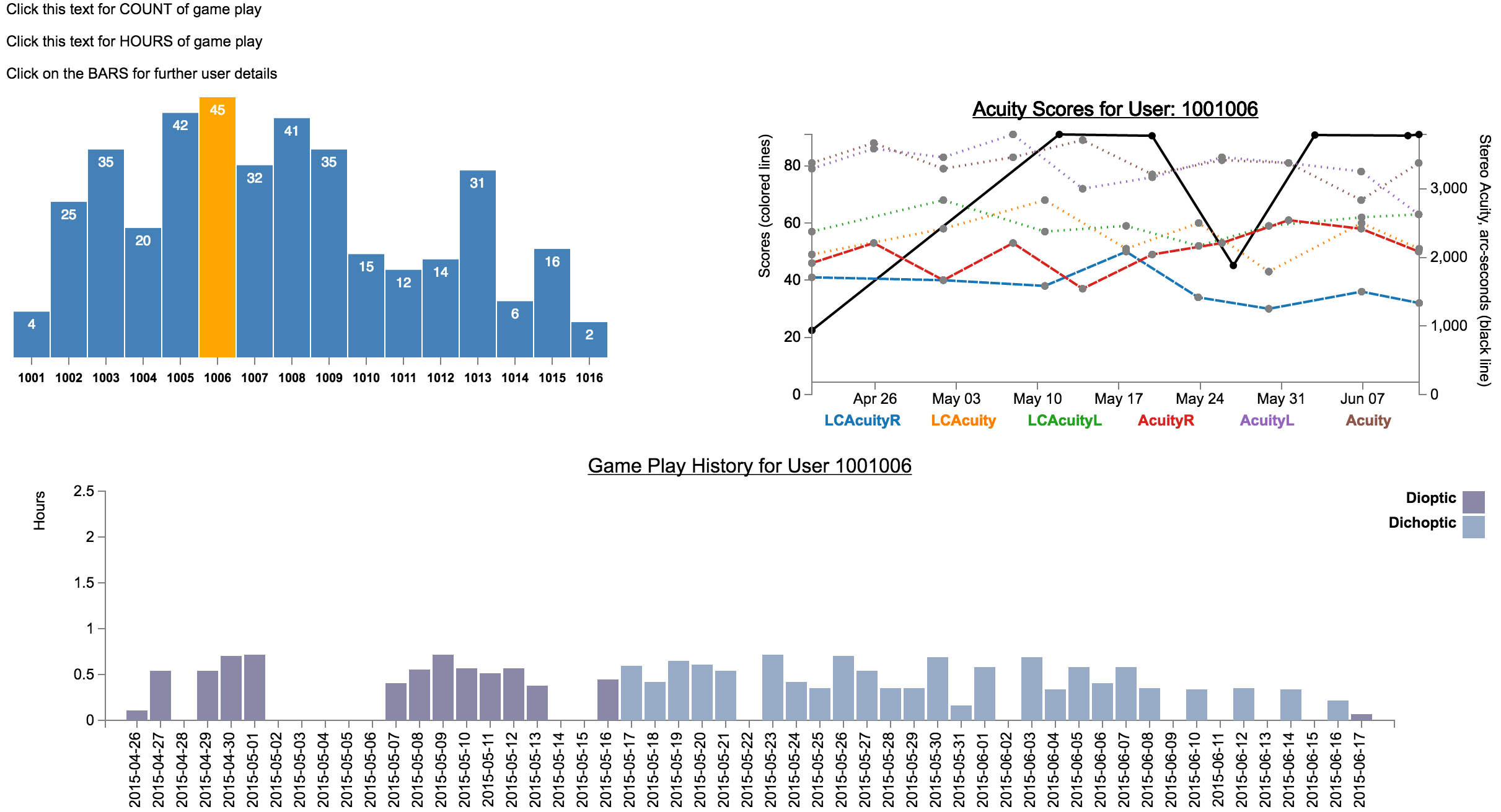
This dashboard was created to help Vivid Vision and UCSF quickly understand how patient were doing during a clinical study. This study was determining the effectiveness of Virtual Reality gaming software to strengthen and correct amblyopia (lazy eye). The data-set you see here was fictionalized to protect patient privacy.